Every second, millions of people around the world tap their smartphones to request an Uber ride, triggering a cascade of technological processes that seem almost magical in their simplicity and speed. Within moments, a nearby driver receives the request, accepts it, and navigation begins — all happening so seamlessly that users rarely consider the sophisticated technology stack making it possible. Behind this effortless experience lies one of the most complex and innovative technology platforms ever built for consumer services.
Uber’s technology stack represents far more than just a ride-hailing app. It’s a comprehensive ecosystem of mobile applications, distributed computing systems, real-time data processing, advanced GPS technologies, secure payment infrastructure, and intelligent algorithms working in perfect harmony. Understanding how these components integrate reveals not only Uber’s technical brilliance but also provides insights into the future of on-demand services and smart city infrastructure. This deep dive explores the foundational technologies that transformed a simple idea into a global transportation revolution.
The Mobile Application Layer: User Interface Meets Power
At the most visible layer of Uber’s technology stack sit the mobile applications — the rider app and driver app that serve as the primary touchpoints for the platform’s 137 million monthly active users. These applications are far more sophisticated than they appear, built using native development frameworks for both iOS and Android to ensure optimal performance and seamless integration with device-specific features.
For iOS applications, Uber leverages Swift and Objective-C along with Apple’s CoreLocation framework, which provides services for determining a device’s geographic location using all available onboard hardware including Wi-Fi, GPS, Bluetooth, magnetometer, barometer, and cellular hardware. The CoreLocation framework is already built into every iPhone, but Uber’s integration extends far beyond basic implementation, utilizing advanced features for background location tracking, geofencing, and precision positioning.
On the Android side, Uber employs similar location services but with additional customizations to handle the fragmentation across thousands of different device models. The company has even developed proprietary GPS improvements that significantly enhance location accuracy in challenging urban environments where tall buildings create signal interference and multipath errors. This enhancement uses particle filtering combined with 3D map data and ray tracing to correct GPS errors that can reach hundreds of meters in dense city centers.
Real-Time Synchronization and State Management
What makes Uber’s mobile apps truly remarkable is their ability to maintain real-time state synchronization across millions of devices simultaneously. When a driver moves, their location updates in real-time on the rider’s screen. When surge pricing activates in a specific neighborhood, all nearby users see updated fare estimates instantly. This requires sophisticated state management systems and efficient data synchronization protocols that minimize battery drain while maximizing responsiveness.
The apps employ WebSocket connections for persistent, bi-directional communication with backend services, allowing the server to push updates to devices without constant polling. This architecture enables features like live driver tracking, real-time fare updates, and instant notification delivery while conserving device resources and reducing data usage.
GPS and Location Technology: Precision in Complex Environments
Location accuracy forms the absolute foundation of Uber’s service. If the system cannot accurately determine where riders and drivers are located, the entire platform fails. This challenge becomes particularly acute in urban canyons — streets surrounded by tall buildings that block, reflect, and scatter GPS signals, creating errors that standard GPS receivers cannot overcome.
Traditional GPS receivers rely on signals from satellites to calculate position through a process called trilateration. Each satellite broadcasts its location and the time the signal was transmitted. By measuring how long signals take to arrive from multiple satellites, the receiver can calculate distances and determine its position. However, this approach assumes clear line-of-sight between satellites and the receiver, an assumption that fails spectacularly in cities where buildings block and reflect signals.
Uber’s Sensing, Inference, and Research team developed a revolutionary approach called probabilistic shadow matching combined with particle filtering. Instead of simply accepting the location reported by the phone’s GPS receiver, the system considers the 3D geometry of buildings and uses ray tracing to predict where satellite signals might be blocked or reflected. The particle filter maintains thousands of possible location hypotheses, continuously updating their probability weights based on incoming GPS measurements and the predicted signal environment.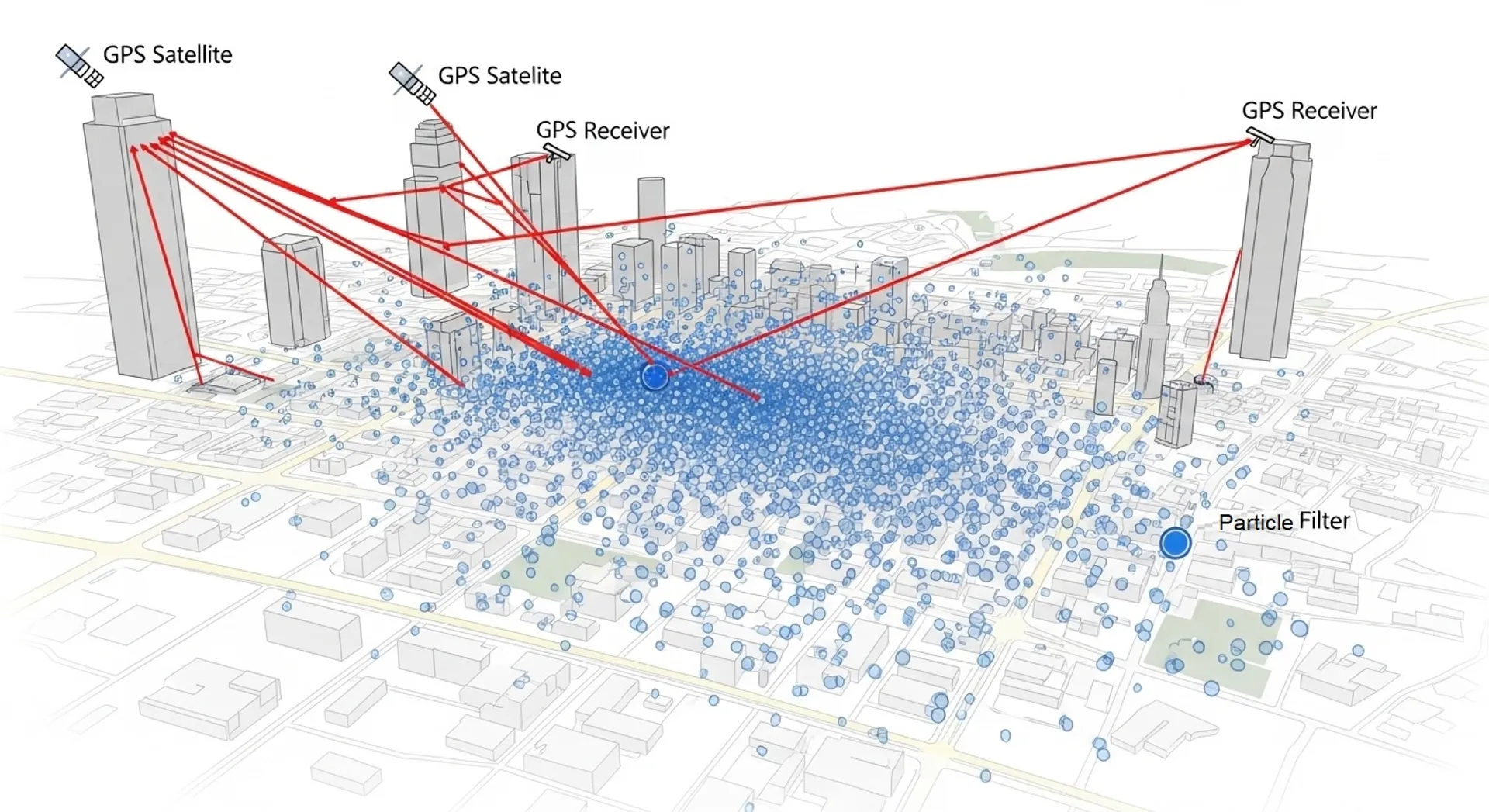
Advanced GNSS Integration
Beyond GPS, Uber’s location technology integrates signals from multiple global navigation satellite systems including GLONASS (Russia), Galileo (European Union), BeiDou (China), and IRNSS (India). This multi-constellation approach, collectively referred to as GNSS (Global Navigation Satellite Systems), significantly improves accuracy and reliability. In open areas, receivers can process signals from up to 20 or more satellites simultaneously, providing extra robustness against noise, signal blockages, and atmospheric interference.
The company’s GPS improvements resulted in a software upgrade for Android phones that significantly enhances location accuracy in urban environments. This upgrade doesn’t require new hardware — it’s purely a software solution leveraging cloud computing power to perform complex calculations that would be impossible on mobile devices alone.
Payment Processing Infrastructure: Security and Seamless Transactions
One of Uber’s most transformative innovations was eliminating cash transactions from the ride experience. This cashless system removes human-to-human currency transfers, making rides more convenient, secure, and traceable. However, implementing this seemingly simple feature requires navigating complex regulatory frameworks and implementing rigorous security standards.
Uber must comply with the Payment Card Industry Data Security Standards (PCI DSS), a comprehensive set of requirements designed to ensure that all companies processing, storing, or transmitting credit card information maintain secure environments. These standards are enforced globally to protect both rider and driver financial information from breaches and fraud.
Rather than building payment processing infrastructure from scratch, Uber partners with specialized payment processors. The company’s long-standing partnership with Braintree, a division of PayPal, provides the backbone for processing millions of daily transactions. Braintree specializes in mobile and web payment systems for ecommerce companies, offering robust APIs that integrate seamlessly with Uber’s platform.
Multi-Payment Method Support
In 2025, Uber supports an extensive array of payment methods to accommodate global users. Beyond traditional credit and debit cards, the platform integrates with digital wallets like Apple Pay, Google Pay, and PayPal. In some markets, Uber even accepts cryptocurrency payments, reflecting the growing adoption of blockchain technology in financial transactions.
Regional customization plays a crucial role in payment strategy. In markets where credit card penetration remains low, Uber maintains cash payment options while still leveraging its technology for ride tracking, matching, and quality assurance. The system accommodates region-specific payment gateways to ensure users can pay through their preferred local methods, whether that’s UPI in India, Alipay in China, or various other regional platforms.
Backend Architecture: Microservices and Distributed Systems
Behind the mobile apps and user-facing features operates a massive backend infrastructure built on microservices architecture. This design approach breaks the platform into hundreds of small, independent services that each handle specific functions — user authentication, ride matching, route calculation, pricing, notifications, and countless others. Each microservice can be developed, tested, deployed, and scaled independently without affecting the entire system.
The transition to microservices represented a fundamental architectural shift for Uber. In the company’s early days, the platform operated on a monolithic architecture using Python, MySQL, and MongoDB for backend services, with Node.js and Redis powering the dispatch system. As the business grew and requirements became more complex, this monolithic approach created bottlenecks and made rapid iteration difficult.
The microservices architecture enables teams across Uber to work independently on different aspects of the platform. The driver matching team can deploy improvements to their algorithms without coordinating with the payment processing team. The routing engine can be updated without affecting the customer support systems. This independence dramatically accelerates development velocity and reduces the risk of system-wide failures.
Service Communication and API Gateway
With hundreds of microservices running simultaneously, managing communication between services becomes critical. Uber employs API gateways that route requests to appropriate services, handle authentication and authorization, implement rate limiting, and provide monitoring and analytics. These gateways serve as the single entry point for client applications, abstracting the complexity of the underlying microservices architecture.
Inter-service communication relies heavily on both synchronous REST APIs and asynchronous message passing through systems like Apache Kafka. This hybrid approach allows services to request immediate responses when needed while also supporting event-driven architectures where services react to events published by other services without direct coupling.
Data Processing and Storage: Managing Petabytes at Scale
Uber generates and processes an extraordinary volume of data — from GPS coordinates updated every few seconds for millions of active drivers, to transaction records, user interactions, sensor data from autonomous vehicle testing, and countless other data streams. Managing this information requires sophisticated data infrastructure operating at massive scale.
The foundation of Uber’s data storage strategy involves multiple specialized databases optimized for different use cases. For operational data requiring fast reads and writes — like active ride information, user profiles, and driver status — Uber employs distributed databases that can handle thousands of transactions per second with minimal latency.
For long-term data storage and analytics, the company relies on Hadoop HDFS as the persistent storage layer. Data flowing through Kafka gets persisted in HDFS as raw logs in Avro format, then merged into optimized Parquet format through compaction processes. This compressed, columnar format enables efficient querying through processing engines like Hive, Presto, and Spark, supporting everything from business analytics to machine learning model training.
Redis for Real-Time Caching
Speed is absolutely critical for Uber’s operations. When a rider requests a trip, the system must respond within milliseconds to provide a good user experience. Querying databases for every piece of information would create unacceptable latency, so Uber implements extensive caching using Redis, an in-memory data structure store.
Redis caches frequently accessed data like driver locations, active ride states, pricing information, and user preferences. With data stored in RAM rather than on disk, Redis delivers sub-millisecond response times, enabling the split-second decision-making required for efficient ride matching and routing. The